Center bias outperforms image salience but not semantics in accounting for attention during scene viewing
Abstract
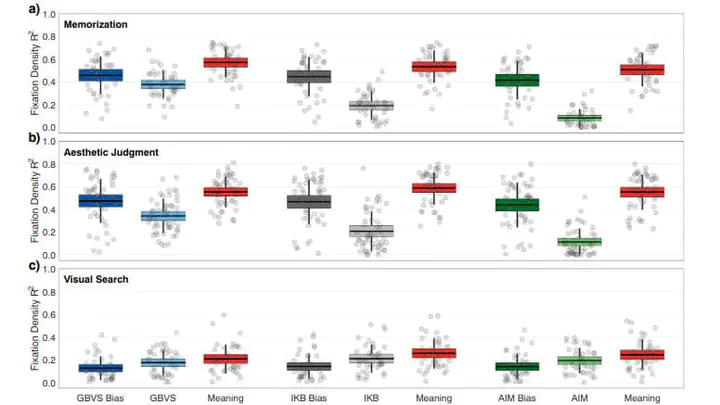
How do we determine where to focus our attention in real-world scenes? Image saliency theory proposes that our attention is ‘pulled’ to scene regions that differ in low-level image features. However, models that formalize image saliency theory often contain significant scene-independent spatial biases. In the present studies, three different viewing tasks were used to evaluate whether image saliency models account for variance in scene fixation density based primarily on scene-dependent, low-level feature contrast, or on their scene-independent spatial biases. For comparison, fixation density was also compared to semantic feature maps (Meaning Maps; Henderson & Hayes, Nature Human Behaviour, 1, 743–747, 2017) that were generated using human ratings of isolated scene patches. The squared correlations between scene fixation density and each image saliency model’s center bias, each full image saliency model, and meaning maps were computed. The results showed that in tasks that produced observer center bias, the image saliency models on average explained 23% less variance in scene fixation density than their center biases alone. In comparison, meaning maps explained on average 10% more variance than center bias alone. We conclude that image saliency theory generalizes poorly to real-world scenes.