Looking for Semantic Similarity: What a Vector Space Model of Semantics Can Tell Us About Attention in Real-world Scenes
Abstract
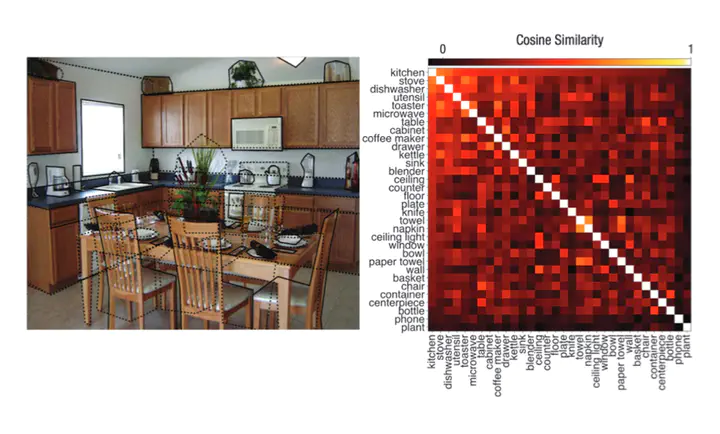
Object semantics are theorized to play a central role in where we look in real-world scenes, but are poorly understood because they are hard to quantify. Here we tested the role of object semantics by combining a computational vector space model of semantics with eye tracking in real-world scenes. We found evidence that the more semantically similar a regions’ objects were to the other objects in the scene and the scene category, the more likely that region was to capture viewer’s attention. This result is especially striking given that the semantic object representations were generated independent of any visual scene input. The results provide evidence that humans use their stored semantic representations of objects to help selectively process complex visual scenes, a theoretically important finding with implications for models in a wide range of areas including cognitive science, linguistics, computer vision, and visual neuroscience.