Deep saliency models learn low-, mid-, and high-level features to predict scene attention
Abstract
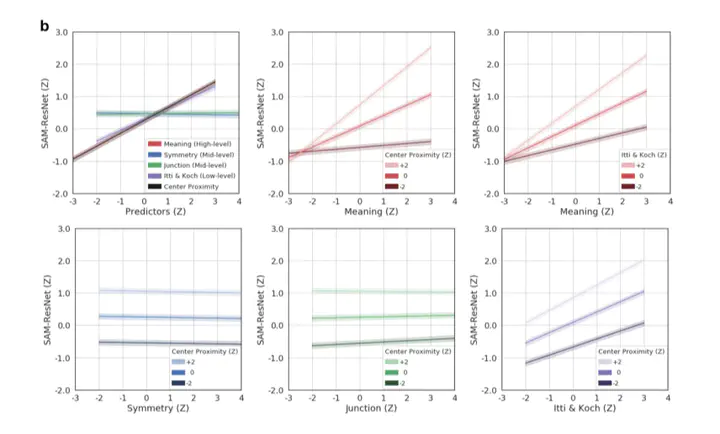
Deep saliency models represent the current state-of-the-art for predicting where humans look in real-world scenes. However, for deep saliency models to inform cognitive theories of attention, we need to know how deep saliency models prioritize different scene features to predict where people look. Here we open the black box of three prominent deep saliency models (MSI-Net, DeepGaze II, and SAM-ResNet) using an approach that models the association between attention, deep saliency model output, and low-, mid-, and high-level scene features. Specifically, we measured the association between each deep saliency model and low-level image saliency, mid-level contour symmetry and junctions, and high-level meaning by applying a mixed effects modeling approach to a large eye movement dataset. We found that all three deep saliency models were most strongly associated with high-level and low-level features, but exhibited qualitatively different feature weightings and interaction patterns. These findings suggest that prominent deep saliency models are primarily learning image features associated with high-level scene meaning and low-level image saliency and highlight the importance of moving beyond simply benchmarking performance.