Meaning guides attention in real-world scene images: Evidence from eye movements and meaning maps
Abstract
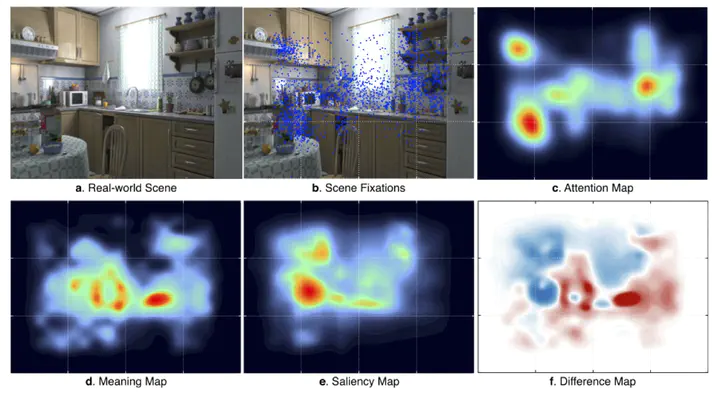
We compared the influence of meaning and of salience on attentional guidance in scene images. Meaning was captured by ‘‘meaning maps’’ representing the spatial distribution of semantic information in scenes. Meaning maps were coded in a format that could be directly compared to maps of image salience generated from image features. We investigated the degree to which meaning versus image salience predicted human viewers’ spatiotemporal distribution of attention over scenes. Extending previous work, here the distribution of attention was operationalized as duration-weighted fixation density. The results showed that both meaning and image salience predicted the duration-weighted distribution of attention, but that when the correlation between meaning and salience was statistically controlled, meaning accounted for unique variance in attention whereas salience did not. This pattern was observed in early as well as late fixations, fixations including and excluding the centers of the scenes, and fixations following short as well as long saccades. The results strongly suggest that meaning guides attention in real-world scenes. We discuss the results from the perspective of a cognitive-relevance theory of attentional guidance.