DeepMeaning: Estimating and Interpreting Scene Meaning for Attention Using a Vision-Language Transformer
Abstract
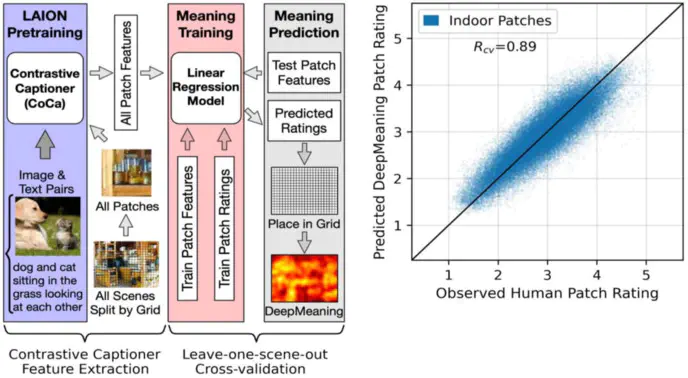
Humans rapidly process and understand real-world scenes with ease. Our stored semantic knowledge gained from experience is thought to be central to this ability by organizing perceptual information into meaningful units to efficiently guide our attention. However, the role stored semantic representations play in attentional guidance remains difficult to study and poorly understood. Here, we apply a state-of-the-art vision-language transformer trained on billions of image-text pairs to help advance our understanding of the role local meaning plays in scene guidance. Specifically, we demonstrate that this transformer-based approach can be used to automatically estimate local scene meaning in indoor and outdoor scenes, predict where people look in these scenes, detect changes in local semantic content, and provide multiple avenues to model interpretation through its language capabilities. Taken together, these findings highlight how multimodal transformers can advance our understanding of the role scene semantics play in scene attention by serving as a representational framework that bridges vision and language.