I study how the brain processes the visual world.
Taylor R. Hayes is a project scientist at the Center for Mind and Brain at the University of California, Davis. He studies how humans use attention to process and understand complex, real-world scenes. In his research he combines eye tracking and behavioral data with computational approaches to study the roles of scene semantics, image features, viewing task, and individual differences during active scene viewing.
Academic CV
Interests
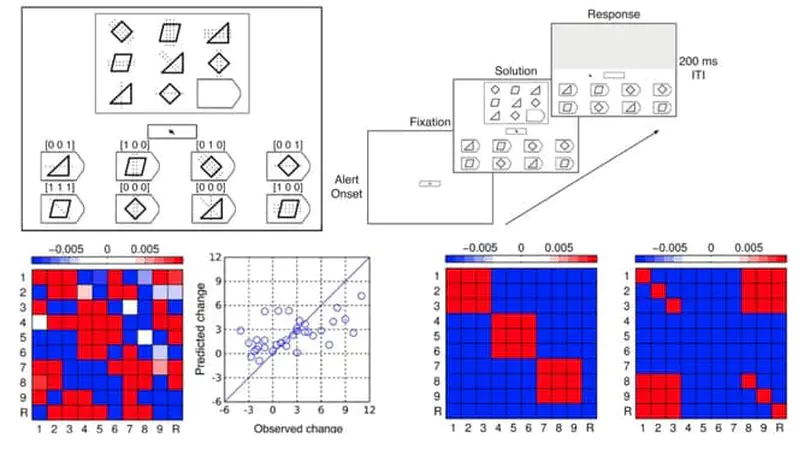
- Attention
- Scene Perception
- Vision Language Models
- Eye Movements
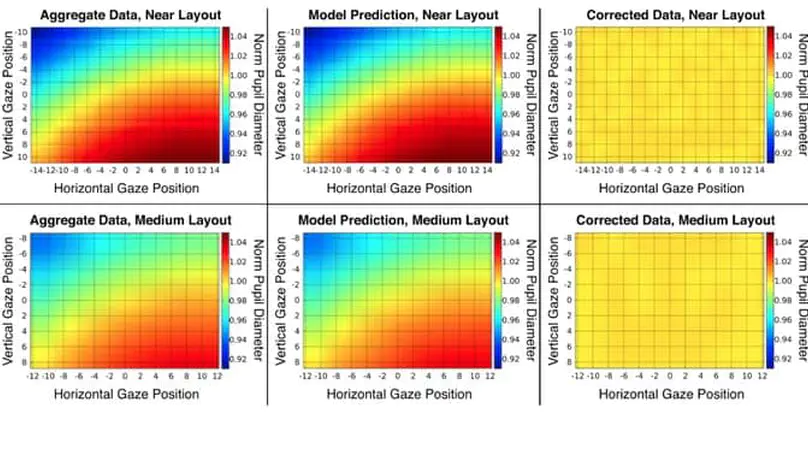
- Pupillometry
Education
PhD Cognitive Psychology, 2015
The Ohio State University
MA Cognitive Psychology, 2011
The Ohio State University
BA Philosophy, 2006
The Ohio State University
Featured Publications

Recent Publications
Quickly discover relevant content by searching publications.
(2025).
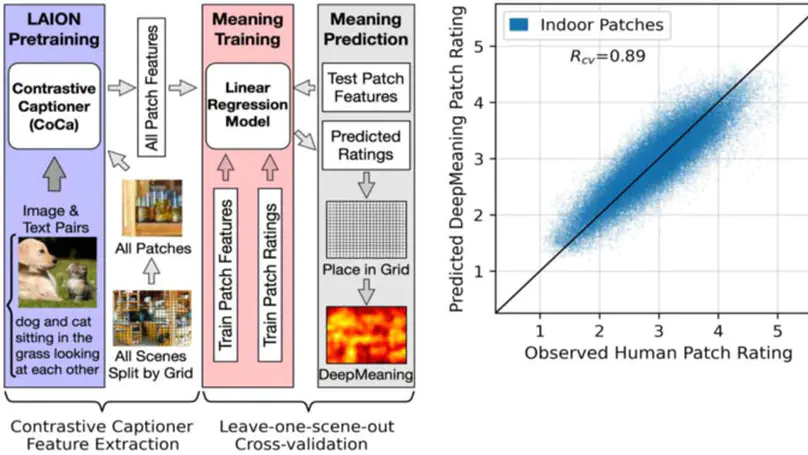
DeepMeaning: Estimating and Interpreting Scene Meaning for Attention Using a Vision-Language Transformer.
Open Mind.
(2024).
The role of local meaning in infants’ fixations of natural scenes.
Infancy.
(2023).
Visual attention during seeing for speaking in healthy aging.
Psychology and Aging.
(2023).
Searching for meaning: Local scene semantics guide attention during natural visual search in scenes.
Quarterly Journal of Experimental Psychology.
(2022).
Scene inversion reveals distinct patterns of attention to semantically interpreted and uninterpreted features.
Cognition.
(2022).
Look at what I can do: Object affordances guide visual attention while speakers describe potential actions.
Attention, Perception, & Psychophysics.
(2022).
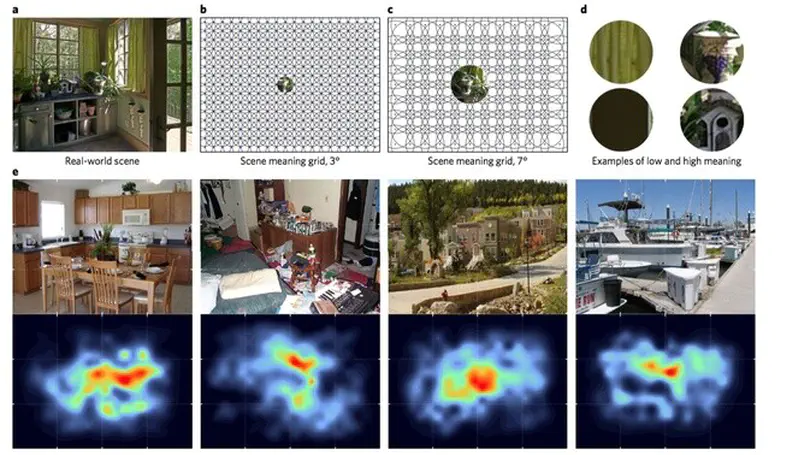
Meaning maps detect the removal of local semantic scene content but deep saliency models do not.
Attention, Perception, & Psychophysics.
(2022).
Rapid extraction of the spatial distribution of physical saliency and semantic informativeness from natural scenes in the human brain.
Journal of Neuroscience.
(2021).
Meaning and expected surfaces combine to guide attention during visual search in scenes.
Journal of Vision.
(2021).
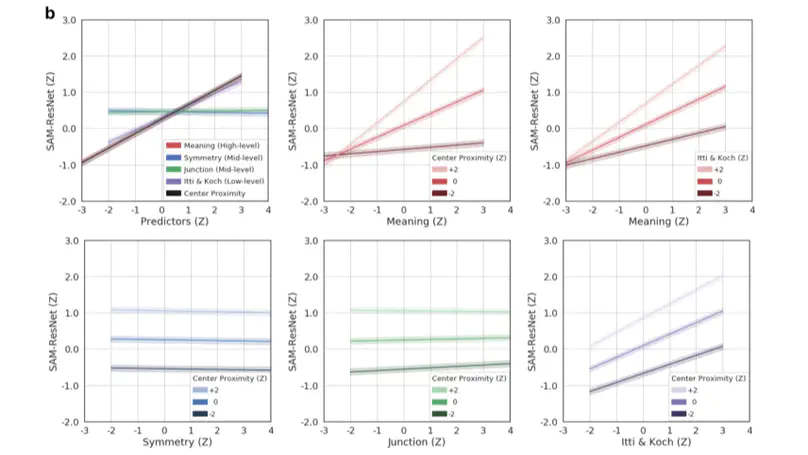
Deep saliency models learn low-, mid-, and high-level features to predict scene attention.
Scientific Reports.
(2021).
Linking patterns of infant eye movements to a neural network model of the ventral stream using representational similarity analysis.
Developmental Science.
(2021).
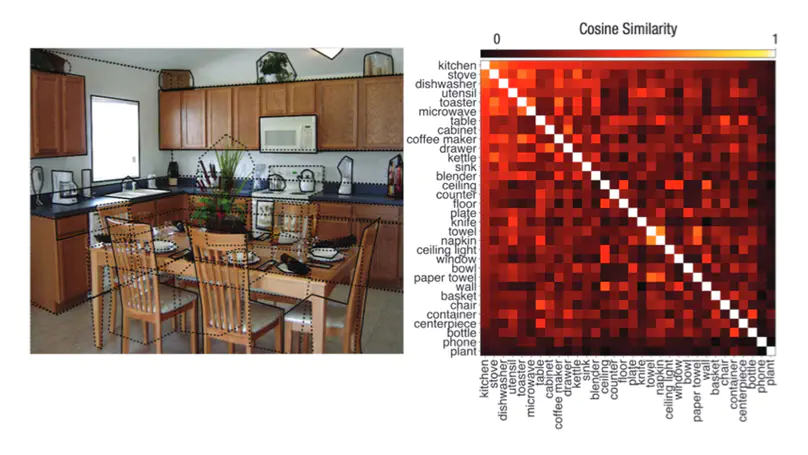
Looking for Semantic Similarity: What a Vector Space Model of Semantics Can Tell Us About Attention in Real-world Scenes.
Psychological Science.
(2021).
Meaning maps capture the density of local semantic features in scenes: A reply to Pedziwiatr, Kümmerer, Wallis, Bethge & Teufel (2021).
Cognition.
(2021).
Developmental changes in natural scene viewing in infancy.
Developmental Psychology.
(2020).
Where the Action Could Be: Speakers Look at Graspable Objects and Meaningful Scene Regions when Describing Potential Actions.
Journal of Experimental Psychology: Learning, Memory, and Cognition.